Pix2Shape: Towards Unsupervised Learning of 3D Scenes from Images Using a View-Based Representation
2020·,,,,,,
Sai Rajeswar
Fahim Mannan
Florian Golemo
Jérôme Parent-Lévesque
David Vázquez
Derek Nowrouzezahrai
Aaron Courville
Abstract
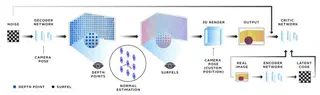
The work presents an unsupervised method for inferring 3D scene information from single images. The approach comprises four components: an encoder that extracts latent 3D representations, a decoder generating 2.5D surfel-based reconstructions, a differentiable renderer synthesizing 2D images, and a critic network discriminating between generated and real images. Unlike voxel or mesh-based methods, this view-dependent approach scales with on-screen resolution. The authors demonstrate consistent learned representations enabling novel viewpoint synthesis and evaluate performance on ShapeNet and a custom 3D-IQTT benchmark for spatial reasoning tasks.
Type
Publication
International Journal of Computer Vision (IJCV)