AlignVLM: Bridging Vision and Language Latent Spaces for Multimodal Document Understanding
2025·,,,,,,,,,,
Ahmed Masry
Juan A. Rodriguez
Tianyu Zhang
Suyuchen Wang
Chao Wang
Aarash Feizi
Others
David Vázquez
Perouz Taslakian
Spandana Gella
Sai Rajeswar
Abstract
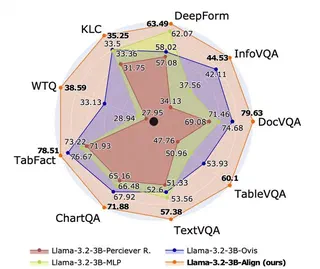
Aligning visual features with language embeddings is a key challenge in vision-language models (VLMs). The performance of such models hinges on having a good connector that maps visual features generated by a vision encoder to a shared embedding space with the LLM while preserving semantic similarity. Existing connectors, such as multilayer perceptrons (MLPs), often produce out-of-distribution or noisy inputs, leading to misalignment between the modalities. In this work, we propose a novel vision-text alignment method, AlignVLM, that maps visual features to a weighted average of LLM text embeddings. Our approach leverages the linguistic priors encoded by the LLM to ensure that visual features are mapped to regions of the space that the LLM can effectively interpret. AlignVLM is particularly effective for document understanding tasks, where scanned document images must be accurately mapped to their textual content. Our extensive experiments show that AlignVLM achieves state-of-the-art performance compared to prior alignment methods. We provide further analysis demonstrating improved vision-text feature alignment and robustness to noise.
Type
Publication
Advances in Neural Information Processing Systems (NeurIPS)