ABOUT
PERSONAL DETAILSI am passionate about Deep Learning and autonomous vehicles. Welcome to my Personal and Academic profile Available as researcher
BIO
ABOUT ME
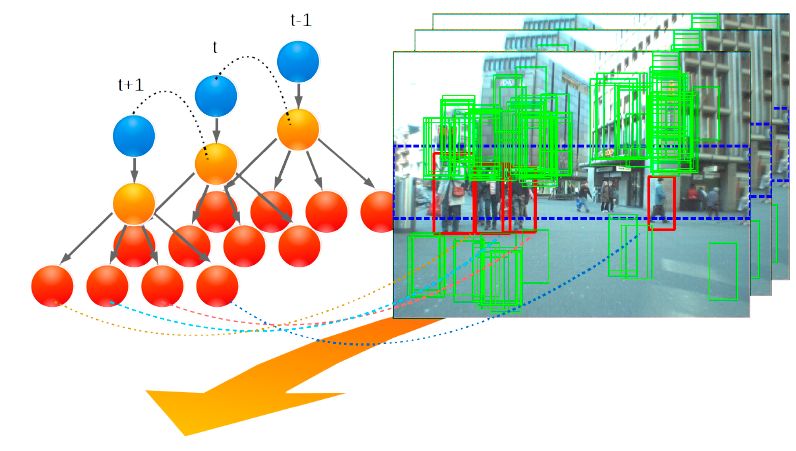
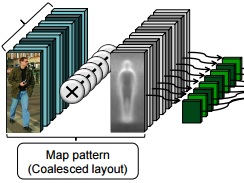
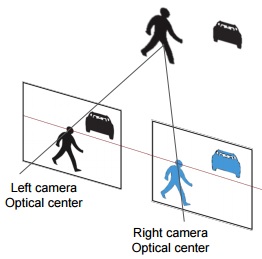
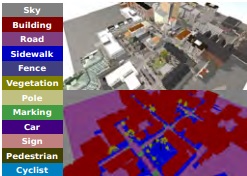
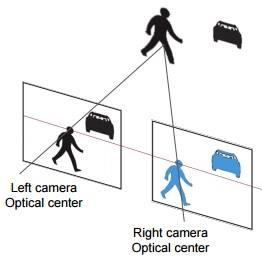
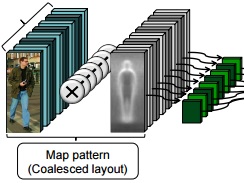
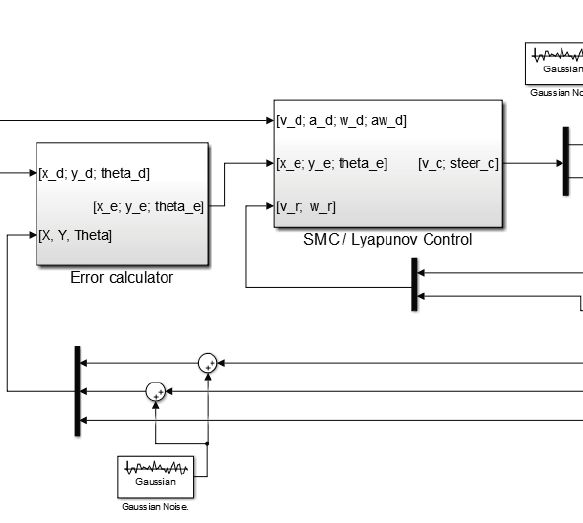
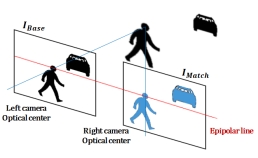
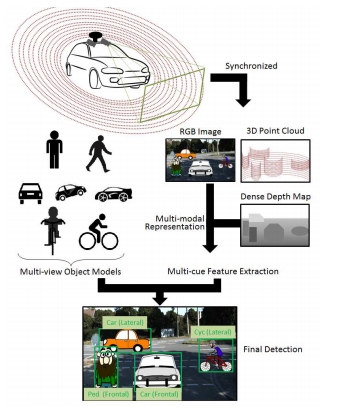
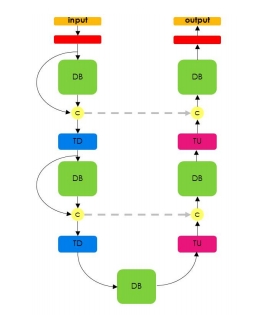
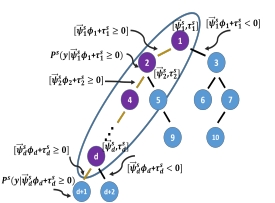
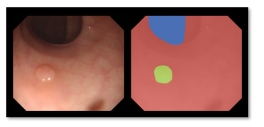
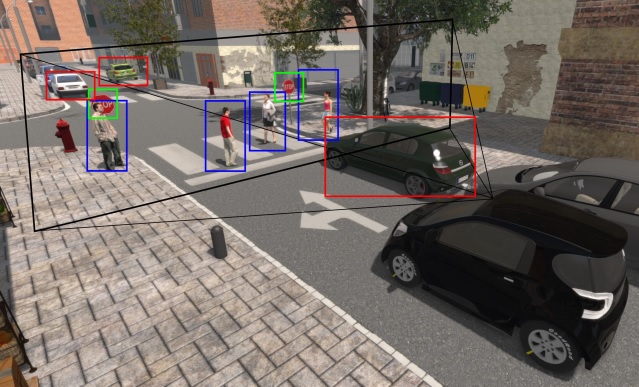
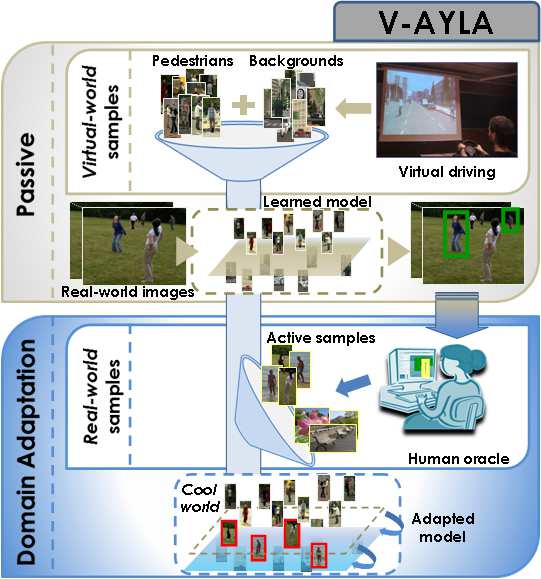
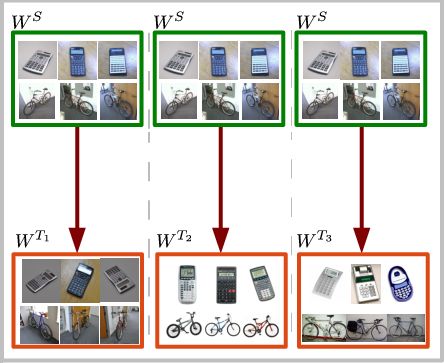
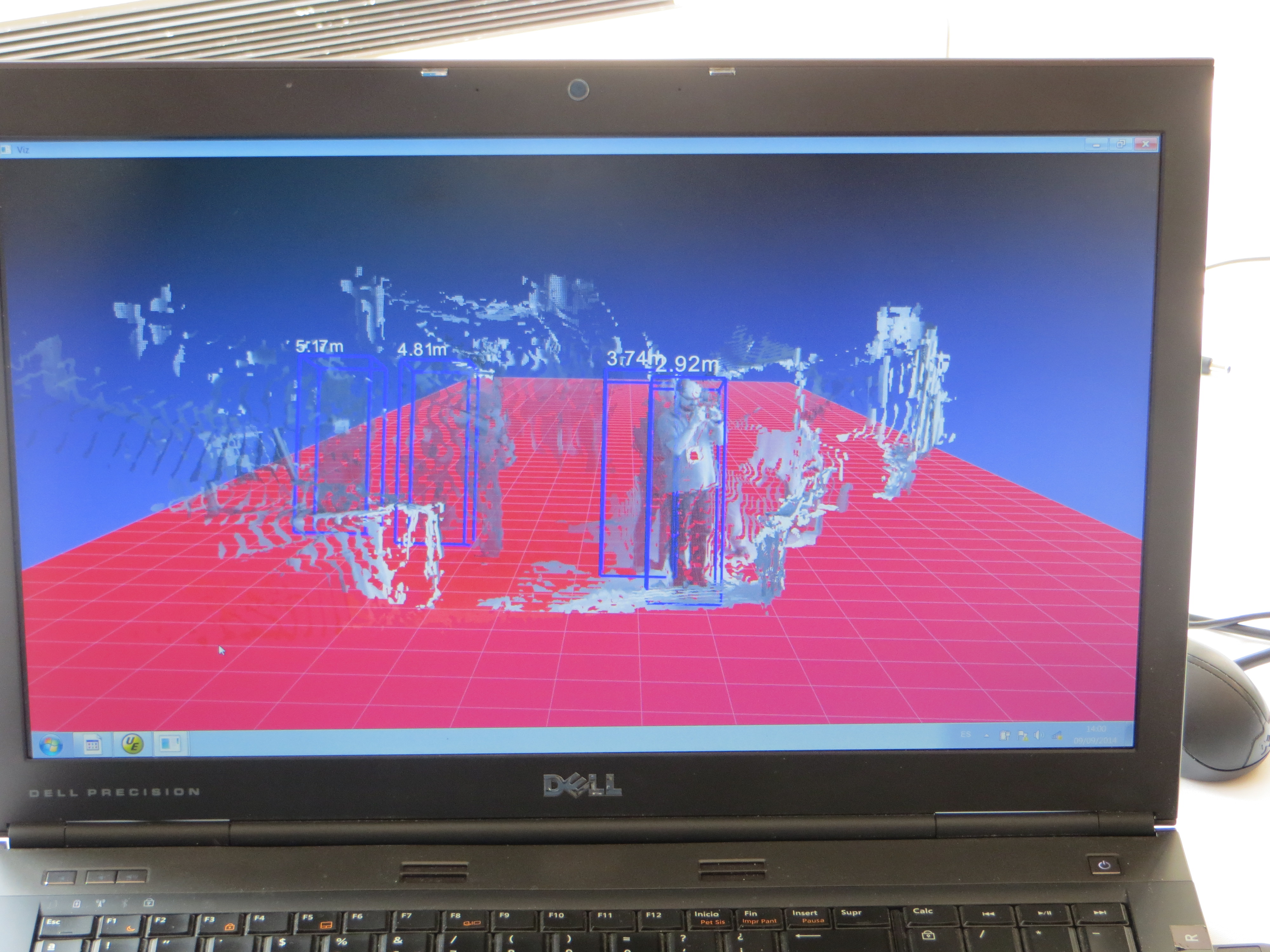
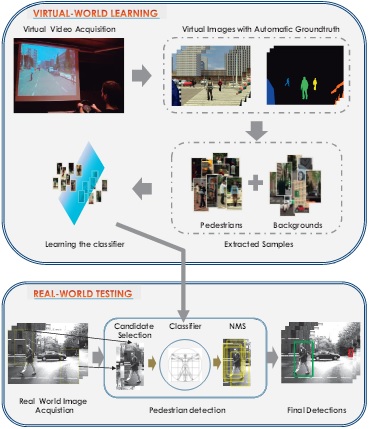
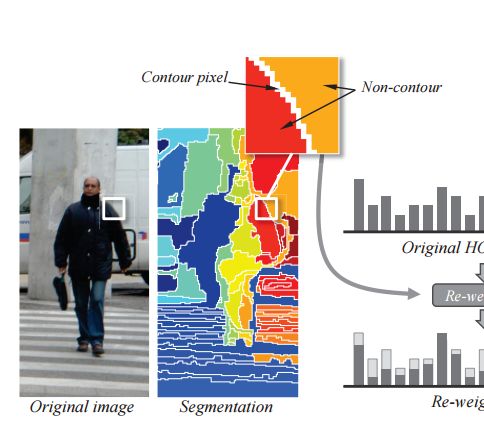
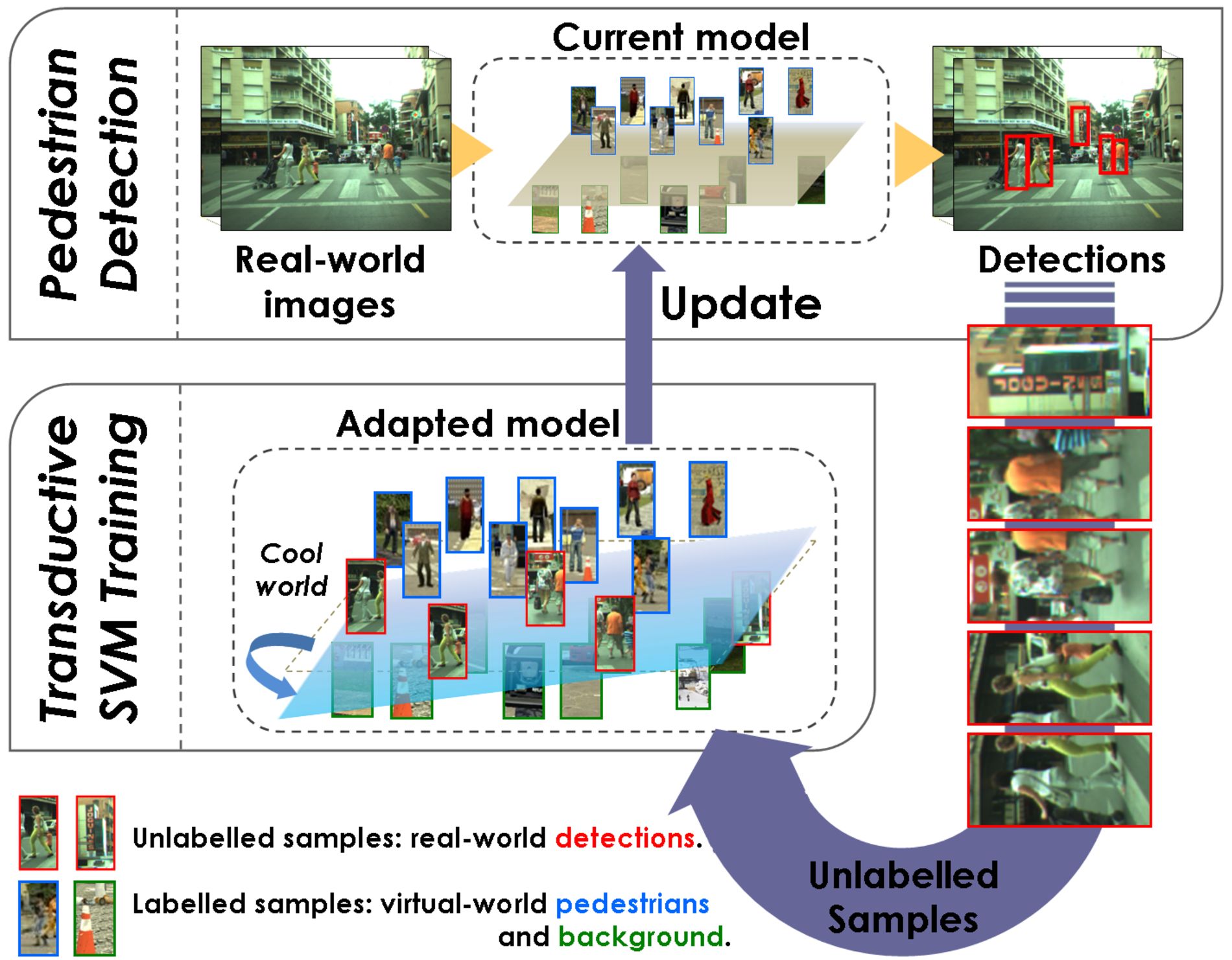
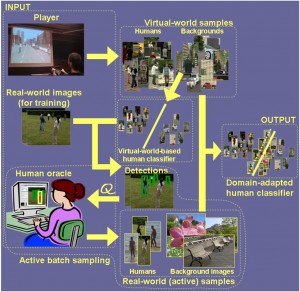
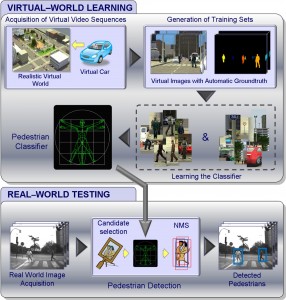
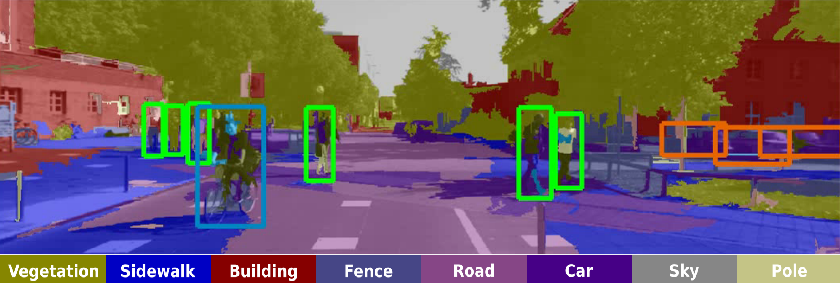
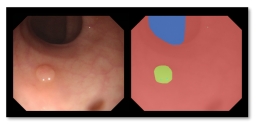
Dr. David Vázquez is a Research Scientist at Element AI. Previously he was a postdoctoral researcher at Computer Vision Center of Barcelona (CVC) and Montreal Institut of Learning Algorithms (MILA) and Asistant Professor in the Department of Computer Science at the Autonomous University of Barcelona (UAB). He received his Ph.D. in Computer Vision (2013), M.Sc. in CV and AI (2009) and B.Sc. in Computer Science (2008) from the UAB. Previously he received the B.Sc. in Software Engineering from the UDC (2006). He has done internships at Daimler AG, UAM and URJC. He is expert in machine perception for autonomous vehicles. His research interests include deep learning, computer vision, robotics and autonomous driving.
He is a recipient of four awards for his Ph.D. Thesis by a Spahish chapter of the Intelligent Transportation Systems Society (ITSS); the Spanish Chapter of the International Association of Pattern Recognition (IAPR); the UAB; and the Centres de Recerca de Catalunya (CERCA); three best paper awards (GTC2016, NIPs-Workshop2011, ICMI2011) and two challenges (CVPR-Challenge2013&2014). David has also participated in industrial projects with companies such as IDIADA Applus+, Samsung and Audi.
David, has been organizer of international workshops in main conferences (i.e., TASK-CV, CVVT, VARVAI) chair at conferences (i.e., IBPRIA), an Editor of the IET Computer Vision journal (IET-CV)and has served as Program Committe of multiple machine learning and vision conferences and Journals (i.e., NIPS, CVPR, ECCV, ICCV, BMVC).
HOBBIES
INTERESTS
I'm passionate about conditioning training group classes such Bodypump, bodycombat, and any aerobics class.
I like experimenting with new vegetarian receips. I'm a Thermomix Master..
I like programming for different platforms such arduino, raspberry py or Jetson.
Watching funny tv series allow me to disconnect and get asleep.